

Throughout Full-stack app post series I’ll try to document whole process of building an web application. I’ll cover common tools and principles that every software engineer has to have in order to write application on its own. Articles are created as part of my learning process of these technologies(or review of tools that I’ve been using for some time). I encourage you to start a discussion in comment section if you think that something could be done easier or more efficient way or you maybe completely disagree with me. Knowledge is built by reading and strengthened with practice and discussion with others.
Intro
Writing code is usually iterative process. You write some code today. Then you add some more code few days later. Then you decide that your code needs refactoring. Then you add a new feature. After running tests you see that this feature broke rest of the code. So now you must manually go through your code and remove all lines that caused problems.
Next time you approach problems differently. Before you add any major changes to your code, you make a copy of directory where your code is. Now if you break something you can revert to your old code. Without even realizing you just made your first step to version control. Although, this is pretty inefficient method of versioning your code but almost everyone start it this way. This works for a simple codebase and when its size is small but isn’t efficient when you start working on larger codebases.
Version control
In order to efficiently work with codebases programmers developed version control. Version control allows you to manage changes to your source code. You can track who did changes and when, revise some code from the past(or even revert to it) etc. First of such tools came almost 50-years ago! SCCS(Source Code Control System) was the pioneer in VC and offered programmers to track changes on single files per on commit(change). SCCS is local version control system which means that all files and changes are stored locally. This worked well in that time because teams were small, internet was still a baby. Codebases eventually became larger and maybe more than one team needed to work on same code base. That lead do development of centralized version control systems. Idea was that there is one central repository which contains all the source code and developers check out files as they need it. This works great: everyone has access to codebase, multi-file commit is enabled, administrators have control over who can do what. Although CVCS seems great it has one major drawback – storing code only in one place represents single point of failure. If central server is unreachable at any moment, nobody can save their changes and collaborate with others. The main representative and most used CVCS tool is Subversion.
The idea of distributed version control system was developed in the 90’s. The idea is that everyone check-out whole repository from central server. Every clone is exact copy of central repository and can be used to restore it if at any point server fails. Today most popular DVCS tool is Git. Git was developed by Linus Torvalds in 2005, when Linux community stopped cooperating with BitKeeper and company revoked free-of-charge from their product.

Working with git
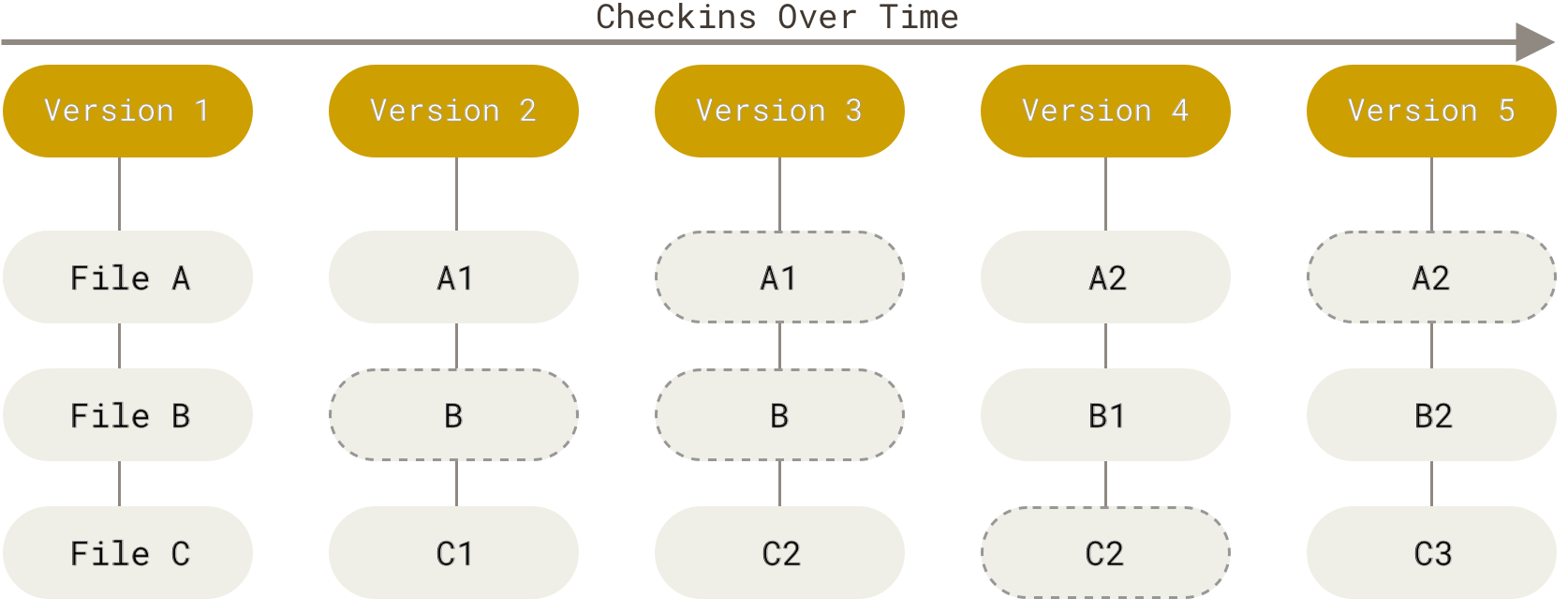
In order to efficiently work with git there are some basic concepts that you need to grasp. Git think of its changes as set of snapshots of a miniature file system. Every time you do commit git “takes picture” of your working directory and store it internal database. Its important to say is that git saves only files that changed and saves link to unchanged files in snapshot.
Almost every operation that is performed on repository is performed locally. This allows as to us benefits of VCS even if we don’t have internet connection and removes need for having central repository. Operations that requires connection are operations for synchronizing local repository with central(pull, push, fetch).
Every commit is marked by its checksum. That grants immutability of committed files and it’s impossible to make any undetected and undocumented change. You can’t fetch corrupted file or lose information without Git knowing it.
Files in git repository can be in three states: committed, staged and modified. Committed file is stored in local database that keep record of all changes. Modified file is changed, but changes aren’t stored in local database. Staged file is changed and is marked for adding to local database.

.git directory holds meta-data about repository and object database of project data. When we clone git repository this is the folder that is cloned. Working directory holds current checkout of some version of project. Sample workflow of working with git is as follows:
- We modify files in working directory
- We mark modified files for commit, which moves them to staging area(git add)
- We commit changes which takes files from staging area and saves snapshot in database.
Basic operations
Although there are many GUI tools to work with git sooner or later you will come to environment where you are destined to use command-line git. Most of the tools don’t even support all commands that git is capable of. But fear not! Even if you aren’t comfortable using command line you can work with git using less than 10 command and knowing approximately twenty commands will make you git master.
| Command | Description |
|---|---|
git init |
Initializes empty repository in current directory |
git clone repo_url |
Clones remote repository into current directory |
git add file_name |
Adds file to staging area |
git commit -m "Commit message" |
Save files from staging area to local database |
git fetch |
Download objects and refs from repository |
git pull |
Fetch and ingrate with local branch or another repository |
git branch branch_name |
Create new branch |
git checkout branch_name |
Switch to another branch |
git diff |
Called without arguments shows changes in working directory(without staged files) |
git log |
Shows log of all commits on current branch |
git status |
Shows status of working directory, current branch, are we behind or ahead of remote branct etc. |
git remote add origin remote_url |
Sets the address of remote repository |
git stash [save|apply|pop] |
Saves or applies staged files to/from stash stack |
git merge branch_name |
Applies changes(commits) from branch_name to current branch |
This may seem overwhelming at first, but you will do most of git work just with commands from this list(remember 80:20 rule?). If you forget what some command does you can always type git help command_name and get detailed man page about that command.
Summary
- Version control is important tool in software development that allows you to track, revise and backup all changes that you do on your codebase
- There are few types of of version control – Local VCS, Centralized VCS and Distributed VCS
- Distributed VCS are the youngest one that get most popularity when Git was created, back in 2005
- Key concept: everyone has exact copy of remote repository which enables them to work offline and provides excellent backup technique if central repository fails
- Git has three file states: modified, staged, commited
- You can do most of the work with git using just about 15 commands
This post is more theoretical but I think that is very important to grasp the basic concepts before you start using git. I saw lot of my colleagues struggling with using git just because they don’t understand the key concepts. In the next article I will write about online git repositories and tools and also what is a git workflow and how to be most efficient. It’s important that you get confident with version control before you actually start coding. On most projects you will collaborate with others so knowing git(or any other VCS, but git is most widely used) is cornerstone of efficient workflow.
If you have any questions or you think that something is missing in the article feel free to leave comment, and if you liked the post subscribe for more content like this.

